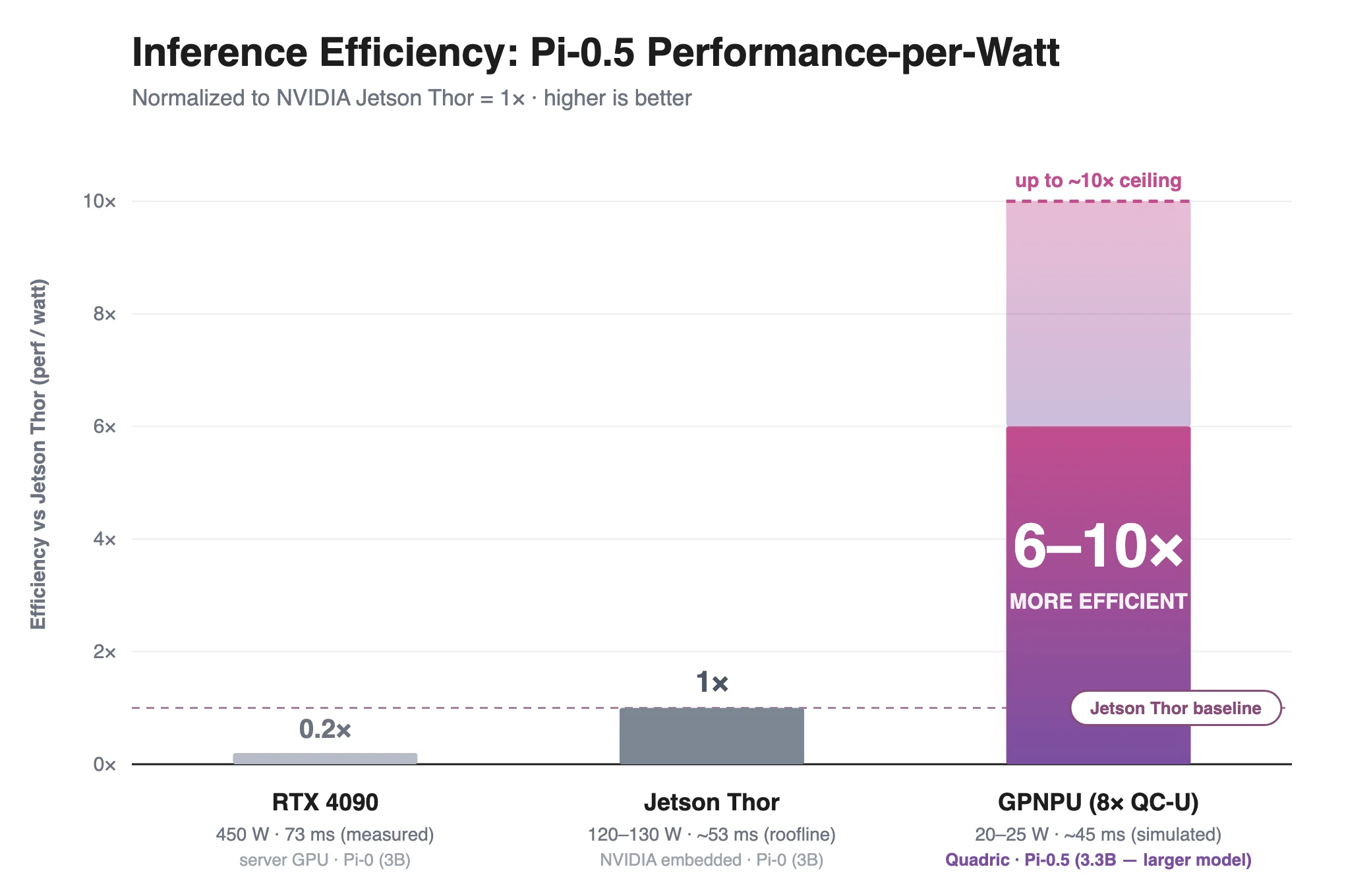
Quadric Runs Pi-0.5 6–10× More Efficiently Than NVIDIA's Jetson Thor
Vision-language-action models dominated discussion at this year's Embedded Vision Summit. Every team building autonomous systems is targeting them. But the hardware question nobody is answering directly: can your NPU actually run one? We benchmarked Pi-0.5 to find out.
At the Embedded Vision Summit this spring, vision-language-action models were everywhere: not as a preview of coming work, but as something robotics teams are actively building toward. If you design silicon for robots or autonomous vehicles, the question is no longer whether you'll encounter VLAs, it's whether your chip can run them without a performance penalty that makes the whole effort pointless.
This post covers what VLAs are, why they stress hardware differently than the models that came before, and what the benchmark numbers actually look like on real silicon alternatives.
What Is a VLA?
A vision-language-action (VLA) model is an end-to-end neural network that takes camera images, joint positions, and natural-language instructions as inputs and produces a sequence of physical actions as output. Instead of chaining separate perception, planning, and control modules, a single model learns all three together.
The name describes the structure. Three components run in sequence:
- A vision encoder converts camera frames into token representations of the scene
- A language model builds an understanding of what needs to happen based on those vision tokens, a text instruction, and the robot's current state
- Starting from a noise vector of randomized candidate actions, an action expert iteratively refines those actions against the language model's output until they converge on a plausible motion plan
Each component is built from transformer layers — multi-head attention and feed-forward networks — that SoC architects already know from ViT and LLM work. The core compute primitives are familiar, but the novelty is in how the three stages connect, how they are trained jointly, and a small number of new operators the action expert introduces.
Pi-0.5: A Concrete Example
Pi-0.5 is a 3.3-billion-parameter open-source VLA from Physical Intelligence. It's a useful benchmark reference because the weights and architecture are public and there is measured performance data from independent research.
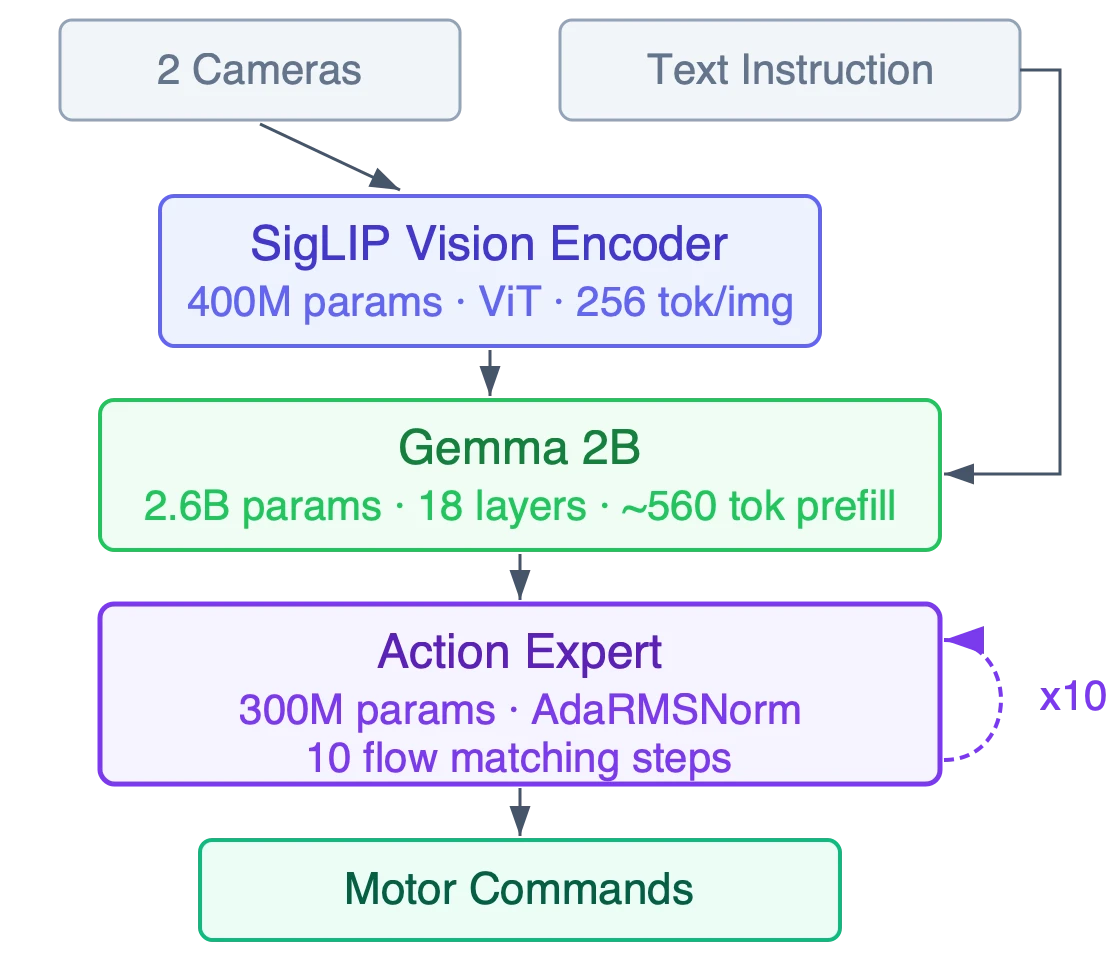
The model processes input across three stages:
- SigLip encoder (~400M parameters): A vision transformer (ViT) that breaks each camera image into 14x14-pixel patches, producing a 16x16 grid of 256 patch tokens per camera; this stage is compute-dominated.
- Gemma 2B (~2.6B parameters): A decoder-only LLM that takes the vision tokens, a task instruction, and robot joint positions. Structurally this is LLM prefill: heavy on both compute and memory bandwidth, since 2.6B parameters move through DRAM on every inference regardless of what optimizations are applied.
- Action expert (~300M parameters): A transformer decoder that runs a refinement loop roughly 10 times per inference. In a process called "flow matching," each iteration asks how the current candidate actions should be corrected given the model's full understanding of the scene and task. After 10 steps, the model outputs roughly 50 action tokens.
The action expert uses AdaRMSNorm (adaptive RMS normalization), an operator that conditions normalization parameters on the current refinement step. Because AdaRMSNorm does not appear in standard ViT or LLM stacks, it's almost certainly absent from the fixed-function accelerator in any heterogeneous NPU; on those architectures it has to fall back to the paired CPU or DSP, collapsing performance.
The three stages make competing demands on hardware: the vision encoder wants sustained compute throughput and the language model wants both compute and bandwidth. The action expert loop is lighter per step but runs 10 times over, and it requires general-purpose programmable execution for its custom normalization.
Why Existing Embedded Options Fall Short
The GPU path
The reference point: Pi-0 on an Nvidia RTX 4090 takes 73 milliseconds (Black et al., arXiv 2410.24164, three cameras, BF16). The RTX 4090 draws 450 watts; it's the server-class baseline, not an embedded target.
Nvidia's Jetson Thor is the nearest GPU-class embedded option: roughly 120-130 watts with about 517 INT8 TOPS. A published roofline analysis for Pi-0 on Jetson Thor (Jiang et al., arXiv 2602.18397) puts the theoretical best-case latency at 53 milliseconds. Real implementations reach 75-85% of roofline after manual optimization, so Jetson Thor performance in practice lands around 62-70 ms.
The problem is that 120+ watts doesn't fit most embedded autonomous systems: delivery robots, production vehicle sensor modules, and drones simply don't have the thermal budget for a single 120-watt inference processor.
The heterogeneous NPU path
The standard embedded approach pairs a fixed-function NPU with a CPU or DSP: the NPU handles matrix multiplications and everything the NPU can't execute falls back to the programmable core.
For Pi-0.5, this fall back approach creates a problem that compounds across every layer. Transformer operations alternate between MAC-heavy projections that can run on the NPU and non-MAC operations (softmax, layer normalization, and AdaRMSNorm) that have to bounce back to the CPU at every transformer layer, through all three stages and all ten flow-matching iterations.
Research on a 1.8B-parameter LLM running on a heterogeneous NPU (Xu et al., "Fast On-device LLM Inference with NPUs," arXiv 2407.05858) found the NPU idle 37% of the time from fallback overhead alone. Careful manual scheduling reduces that number but doesn't eliminate it, and even if you closed the gap, the constant bus traffic between NPU and CPU costs real power.
For Pi-0.5 specifically, operator partitioning generates 712 NPU-to-CPU round-trips per inference, with 762 MB of extra memory transfers, and that overhead accumulates across all 10 flow-matching steps.
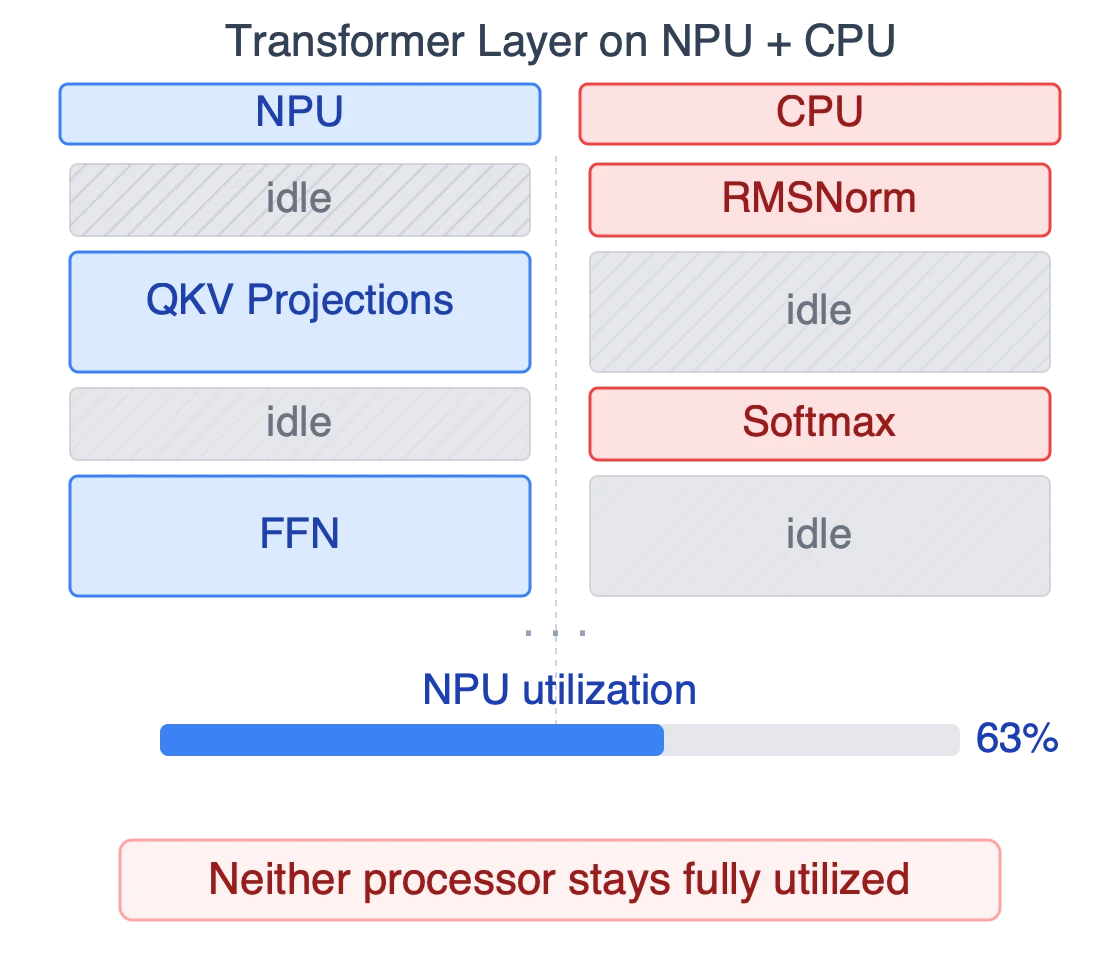
The scheduling difficulty scales with model novelty. Next year's VLAs will introduce operators today's fixed-function NPUs don't recognize, the fallback path instead becomes the primary execution path for whatever is new, and the problem compounds with each generation.
Running Pi-0.5 on Chimera
Quadric's Chimera™ GPNPU (General-Purpose Neural Processing Unit) is a fully programmable array of processing elements (PEs), each containing multiply-accumulate units, a complete 32-bit scalar ALU, local memory, and a mesh connection to adjacent PEs. There's no hardware-managed cache and no separate fallback processor: every operator runs on the same array under software control.
Every operator in Pi-0.5 — including AdaRMSNorm — runs natively on Chimera with no fallback and no round-trips, and here's how it works on the Chimera QC-Perform core with 256 PEs:
- Mapping the vision encoder: SigLIP produces 256 patch tokens per camera from its 16x16 patch grid, mapping one-to-one with QC-Perform's 256 PEs. Projections, dot products, and softmax all execute with data staying in place on the array; nothing reshuffles between stages within a layer. The larger QC-Ultra core (with 1,024 PEs) is able to process four patches per PE across its 32x32 array.
- Weight tiling for the language model: Gemma's feed-forward weights don't all fit in on-chip SRAM at once, so software tiles the weights across the PE array and DMA prefetches the next tile while the current tile is computing, hiding memory latency. This process depends on deterministic software-managed memory; hardware cache in a CPU or DSP introduces non-deterministic eviction that breaks the prefetch overlap.
- Custom operators in place: AdaRMSNorm runs on the same PE array in the same data layout left by the preceding attention block: no dispatch to a separate processor and no data movement to initiate the operation.
Performance Comparison
| RTX 4090 | Jetson Thor | GPNPU (8x QC-Ultra) | |
|---|---|---|---|
| Model | Pi-0 (3B) | Pi-0 (3B) | Pi-0.5 (3.3B) |
| INT8 TOPS | ~1,300 | ~517 | 445 |
| DDR Bandwidth | 1,008 GB/s | 273 GB/s | 273 GB/s |
| Power | 450W | 120-130W | ~11W (cores) |
| E2E Latency | 73 ms (measured) | ~53 ms (roofline) | ~45 ms (simulated) |
Three things matter in reading these numbers.
First: the Jetson Thor figure is a roofline, meaning a theoretical ceiling that assumes perfect, fully-optimized implementation. Realistic performance lands at 75-85% of roofline after significant manual effort, which puts actual Jetson Thor latency in the 62-71 ms range. The Chimera number of 45 ms comes from code running on a cycle-accurate simulator; this is the current implementation, not a ceiling, and optimization headroom remains.
Second: Chimera is running Pi-0.5 (3.3B parameters) while the RTX 4090 and Jetson Thor run Pi-0 (3B parameters). Chimera is able to run the larger model and still comfortably beat the theoretical maximum of the smaller model on Jetson Thor and the measured maximum on the RTX 4090.
Third: DDR bandwidth is matched between Jetson Thor and the Chimera configuration at 273 GB/s, which controls for that variable. The power ratio is roughly 10-to-1: 11 watts for the Chimera cores versus 120-130 watts for Jetson Thor. A complete SoC will certainly add power beyond the processor cores — DDR interfaces and other subsystems push system-level power higher — but a 20-25W chip outrunning a 130W device is a decisive result.
What This Means for Architecture Decisions
The deployment problem for VLAs is not a TOPS problem; a fixed-function NPU can have more than enough matrix throughput and still fail on VLAs because it cannot execute the full operator graph natively. Every fallback boundary adds latency and memory traffic that cascades through 10 flow-matching iterations per inference.
VLA architectures will keep changing, physical Intelligence will revise Pi-0.5, and other teams are shipping competing models with different action expert designs and different conditioning operators. The distance between today's operator set and next year's is only going to grow. A chip team that standardizes on a fixed-function NPU today commits to respinning silicon to keep up, but Chimera's fully programmable execution enables it to adapt just by recompiling.
If you are evaluating processor IP for robotics, autonomous vehicles, or other embedded autonomy applications, contact us to discuss VLA benchmark results and Chimera GPNPU performance data.